いつか、このBlogにも全文検索機能を入れようと思っていたが、先日Drupalの日本語検索、ちゃんと動いてる?N-gramの課題と自然言語処理での改善策、Drupalの日本語検索を改善!自然言語処理を活用したSearch API Japanese Tokenizerモジュールの紹介という記事が出ていたので、この機会にやってみようと重い腰を上げることにした。
まずSearch APIモジュールを適用する。Search APIの日本語版の解説は、DrupalのSearch API入門 概要と始め方【前編】、DrupalのSearch API入門 検索画面の作成と拡張モジュールの使用【後編】がわかりやすい。
依存関係はcomposerが管理してくれるので、モジュールのインストールは
$ composer require 'drupal/search_api_japanese_tokenizer:^1.0@alpha'
./composer.json has been updated
Running composer update drupal/search_api_japanese_tokenizer
Loading composer repositories with package information
Updating dependencies
Lock file operations: 3 installs, 0 updates, 0 removals
- Locking drupal/search_api (1.38.0)
- Locking drupal/search_api_japanese_tokenizer (1.0.0-alpha4)
- Locking u7aro/tinysegmenter-php (v0.2.0)
Writing lock file
Installing dependencies from lock file (including require-dev)
Package operations: 3 installs, 0 updates, 0 removals
- Downloading u7aro/tinysegmenter-php (v0.2.0)
- Downloading drupal/search_api (1.38.0)
- Downloading drupal/search_api_japanese_tokenizer (1.0.0-alpha4)
- Installing u7aro/tinysegmenter-php (v0.2.0): Extracting archive
- Installing drupal/search_api (1.38.0): Extracting archive
- Installing drupal/search_api_japanese_tokenizer (1.0.0-alpha4): Extracting archive
3 package suggestions were added by new dependencies, use `composer suggest` to see details.
Generating autoload files
45 packages you are using are looking for funding.
Use the `composer fund` command to find out more!
No security vulnerability advisories found
で良い。
管理画面で、モジュールの有効化を行って、Search APIの設定を行う。
There are no servers or indexes defined. For a quick start, we suggest you install the Database Search Defaults module.
と警告が出ているので、追加でインストールする。
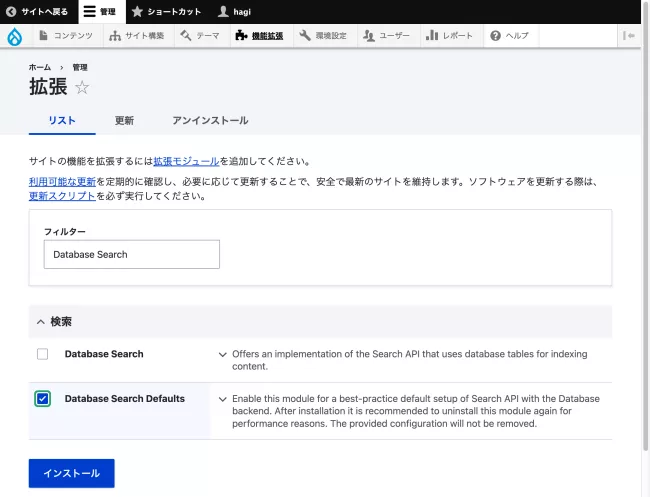
再びSearch APIの設定画面に行くとServerとIndexのBest Practiceが生成されている。
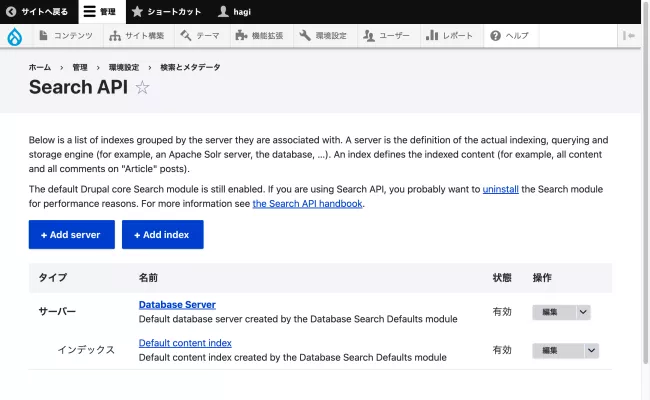
残念ながら、Default content indexはSearch API Japanese Tokenizerが適用されているわけではないので、それを含めてこの設定を見直す。検索対象にしたいのはBlog(記事)だけなので、対象コンテンツを限定する。
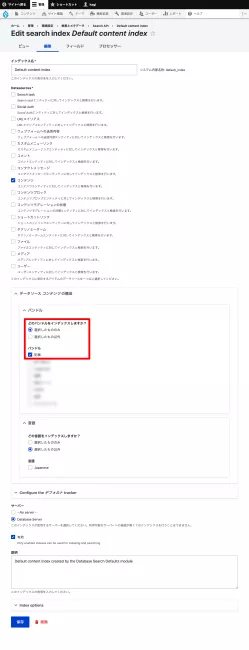
プロセッサーで要約(highlight)とTinySegmenter トークナイザーをオンにして、逆にTokenizer(英語版トークナイザー)をオフにする。関連してStopwords、Transliterationもオフにする。TinySegmenter トークナイザーの設定はデフォルトのままで行く。漢字は最小1文字となっていることを確認。
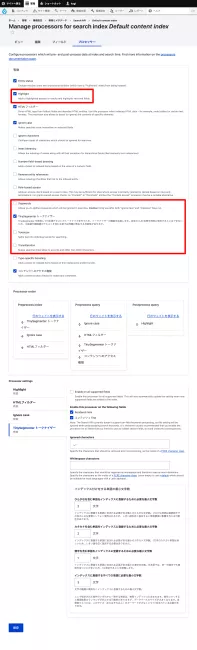
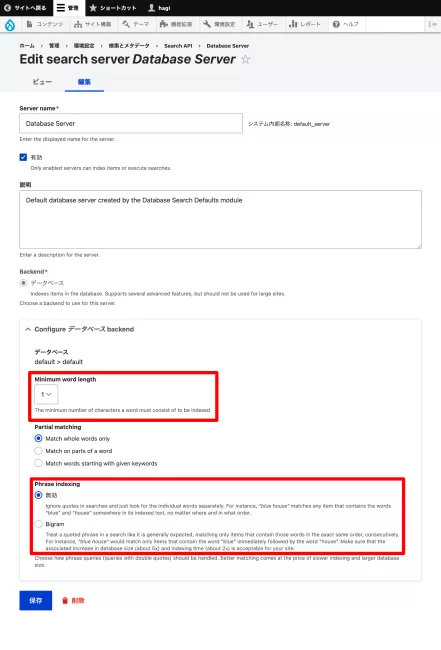
Database Serverの設定も見直す。デフォルトでは最小文字数が3だが、これを1に変更する。ついでに、出現順序は見ない設定にしてインデックスを軽くする。
Default content indexを再び選択して、インデックスを生成する。
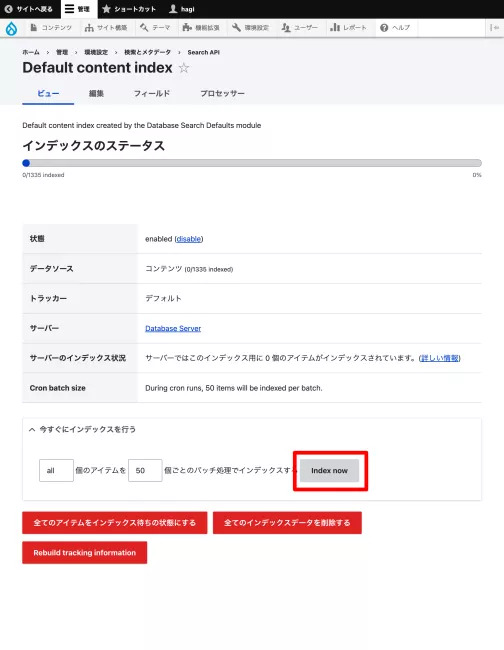
このBlogはGCPのe2-micro(メモリー1GB)と非力だが、待っている間に1218itemのインデックスが終わった。mysqlでsearch_api_db_default_index_textテーブルを見ると434,873行生成されている。一部を掲載しておく。
| entity:node/9:ja | rendered_item | 長い | 553 |
| entity:node/9:ja | rendered_item | 電気代 | 647 |
| entity:node/9:ja | rendered_item | 面積 | 2168 |
| entity:node/9:ja | rendered_item | 頃 | 541 |
| entity:node/9:ja | title | 17 | 8000 |
| entity:node/9:ja | title | サードワークプレース | 8000 |
| entity:node/9:ja | title | 会 | 8000 |
| entity:node/9:ja | title | 定例 | 8000 |
| entity:node/9:ja | title | 年度 | 8000 |
| entity:node/9:ja | title | 研究 | 8000 |
| entity:node/9:ja | title | 終了 | 8000 |
| entity:node/9:ja | title | 部会 | 8000 |
これで、日本語全文検索の準備が整った。Best PracticeでViews(search_content)が生成されているので、/search/contentのページに行って、「ワークフレース」で検索してみる。
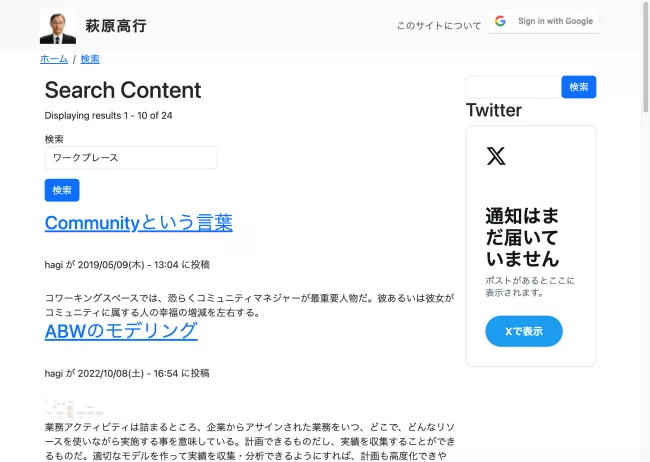
無事に検索できている。通常の検索窓を使うと、結果は以下の通り。
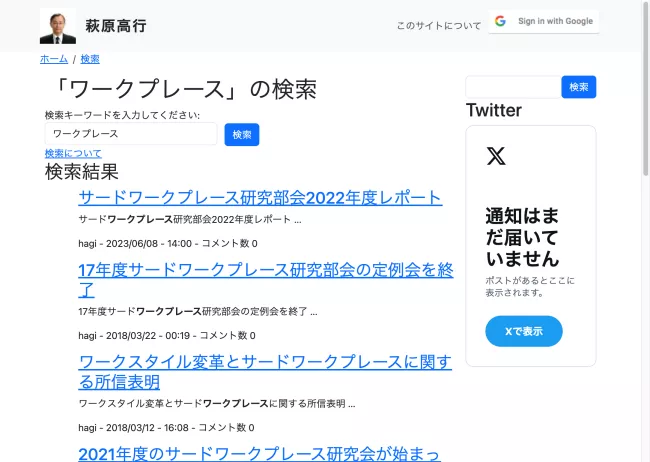
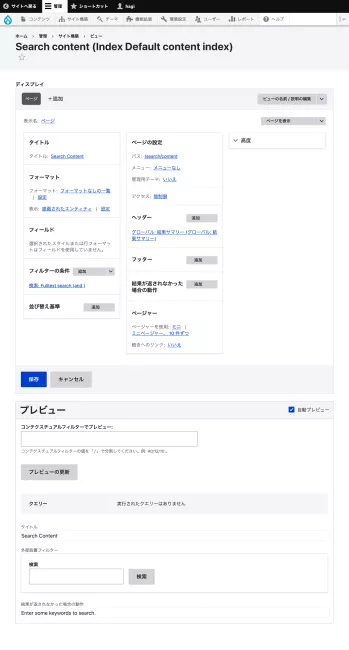
通常検索だと、ワークプレースがハイライトされているのがわかる。Search APIだとhighlightプラグインがこの機能を担っているので、Search content (Index Default content index)ビューに手を入れていく。当初の設定は以下の通り。
検索窓と近い形をhtmlフォーマットで、日付、関連度を加えてViewsを修正してみた。一点、注意しなければいけないのは、フィルター条件: 検索: Fulltext searchのMinimum keyword lengthを1にしないと、短い言葉で検索することができない。
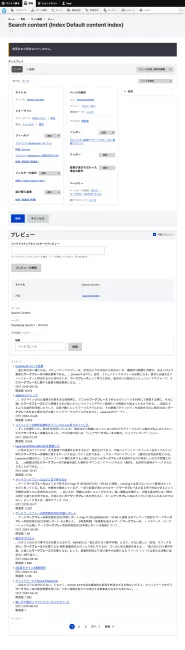
ちょっと気になるのは、「2回目のタリン3週間滞在」でハイライトが出てこないことだ。データベースを見ると
| entity:node/922:ja | rendered_item | ワークプレース | 1138 |
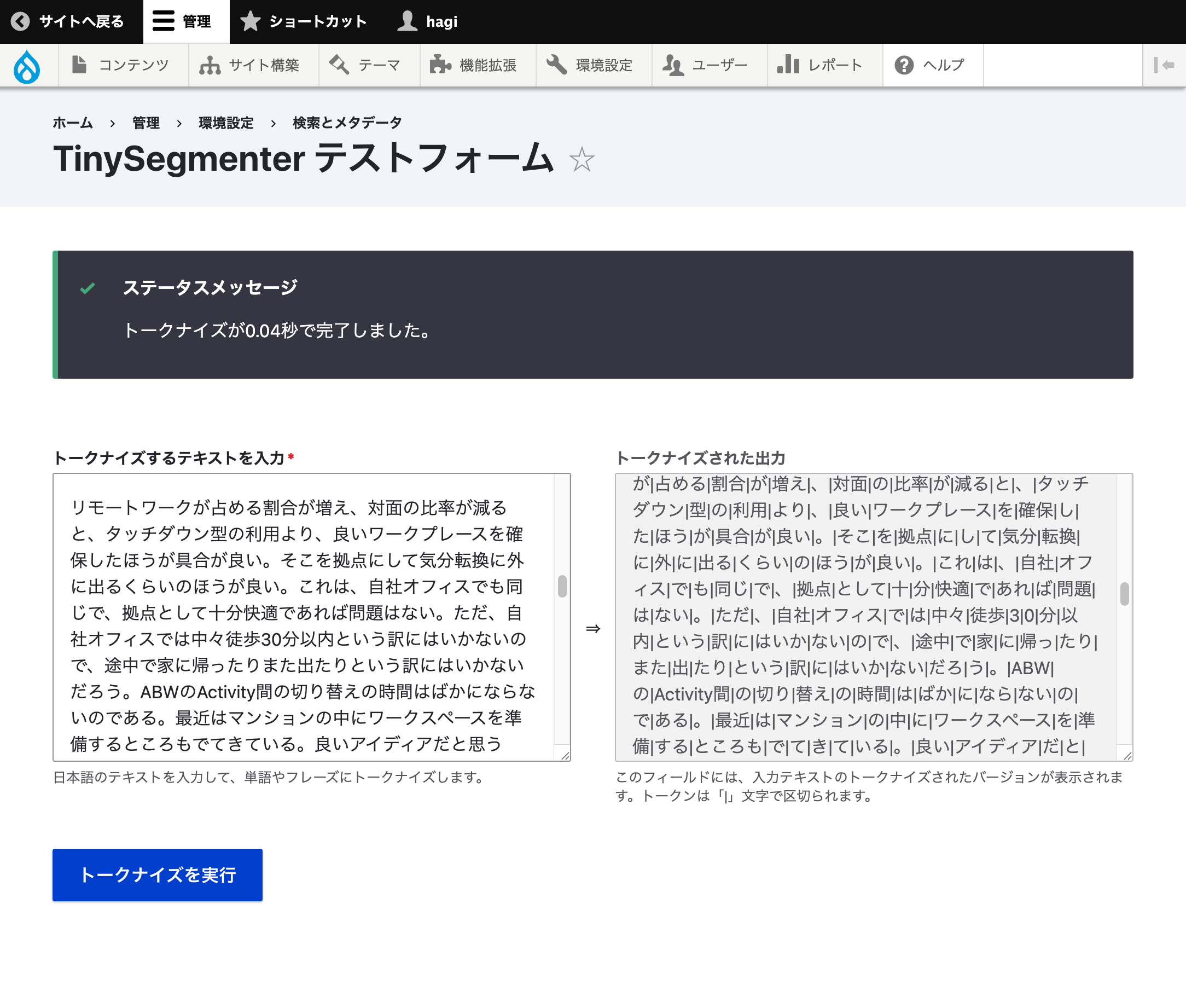
というエントリーがあり、TinySegmenter テストフォームでも切り出しはできている。
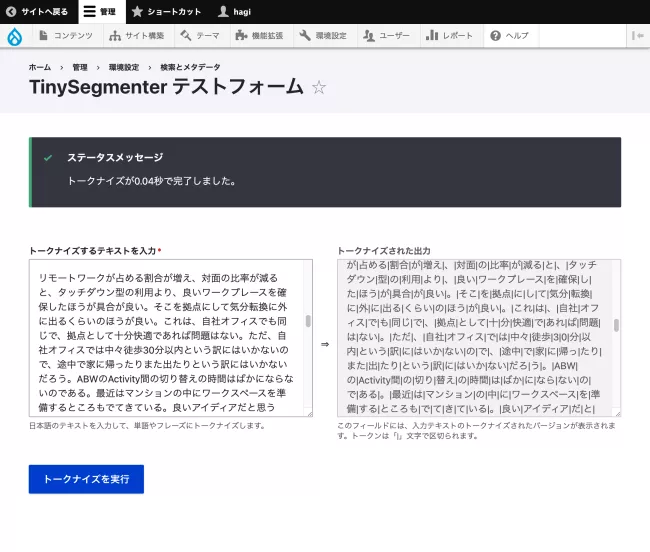
原因は良くわからないが、通常の検索窓でもハイライトがうまく拾えていないケースはあるので、何か言語に依存する問題点があるのかも知れない。
実際に設定してみると、それほどの手はかからない。もちろん、ベストプラクティスによらずに設定することも可能だが、まずはそれに従って改善していくほうが無難だろう。筆者は、当初は冒頭で引用した4つの記事に基づいて手を動かして動作を確認した。特に困難があったわけではないが、本番環境を設定して、この記事を書く段階では、ベストプラクティスを基本に設定した。それによって学べたこともある。